前言
在上一篇博客’微软办公软件接入AI服务‘中,我们在办公软件中引入了AI;这篇博客里我们回归老本行,开始写代码,用AI打造一个私有知识库。
原理介绍
私有知识库
什么是私有知识库呢?我问了一下DeepSeek,它是这样回答的:“私有知识库是指个人或组织拥有并管理的专属知识存储和管理系统,用于集中存储、整理和共享特定领域的知识资源。它可以帮助用户高效管理和利用知识,促进知识的沉淀、共享和创新。”
总的来说,我们如今接触到的知识和信息越来越多了,每天都会查看或编写各种各样的文件或资料,很多时候这些东西都是琐碎的,用的时候又偏偏找不到,如何才能比较容易的查询、检索和获取这些信息?如果说个人还可以自己做整理和归纳,那么一个组织或者公司,如何管理和利用这些资源,并在组织内部实现共享?私有知识库就是一个很不错的选择。
我觉得这个系统要有两个必备的属性,第一是方便检索,不限于使用标题、关键字、内容;第二是应该有一定的私密性,毕竟作为个人或者组织,我们的有些数据是不希望在互联网上曝光的。在之前没有AI的时候,我们要实现第一点都很不容易,虽然可以用ElasticSearch等做传统关键字搜索,但是如果我们连关键字也记错或者要搜索的是图片、视频等,就很乏力了,而我们这次引入了阿里云百炼的向量模型,可以做到更广泛的处理语义理解和非结构化数据的相似性检索。关于第二点,我们这次引入了Milvus向量数据库,所以数据还是保存到本地,在一定程度上保护了我们的数据。
向量、向量数据库
讲到这里,可能很多人就感到蒙圈了,向量是什么,向量模型是什么,向量数据库又是什么;这里开始我写了很多,但由于我的水平有限,干脆直接贴出一个视频链接:向量数据库技术鉴赏;说实话,刚接触时我也是蒙圈的,看完后感觉至少概念上理解了一些。
项目效果
也许上面的介绍还是有些抽象,那么我们先来看看程序实现的效果;举个例子,比如最近《哪吒》很火,我们这些年也看过不少电影,如果我们把自己看过的电影制作成表格,并把它们初始化到向量数据库了,我们就可以让程序帮我们找找有没有《哪吒》类型的电影。
我们csv文件中的数据:

csv文件中的电影数据
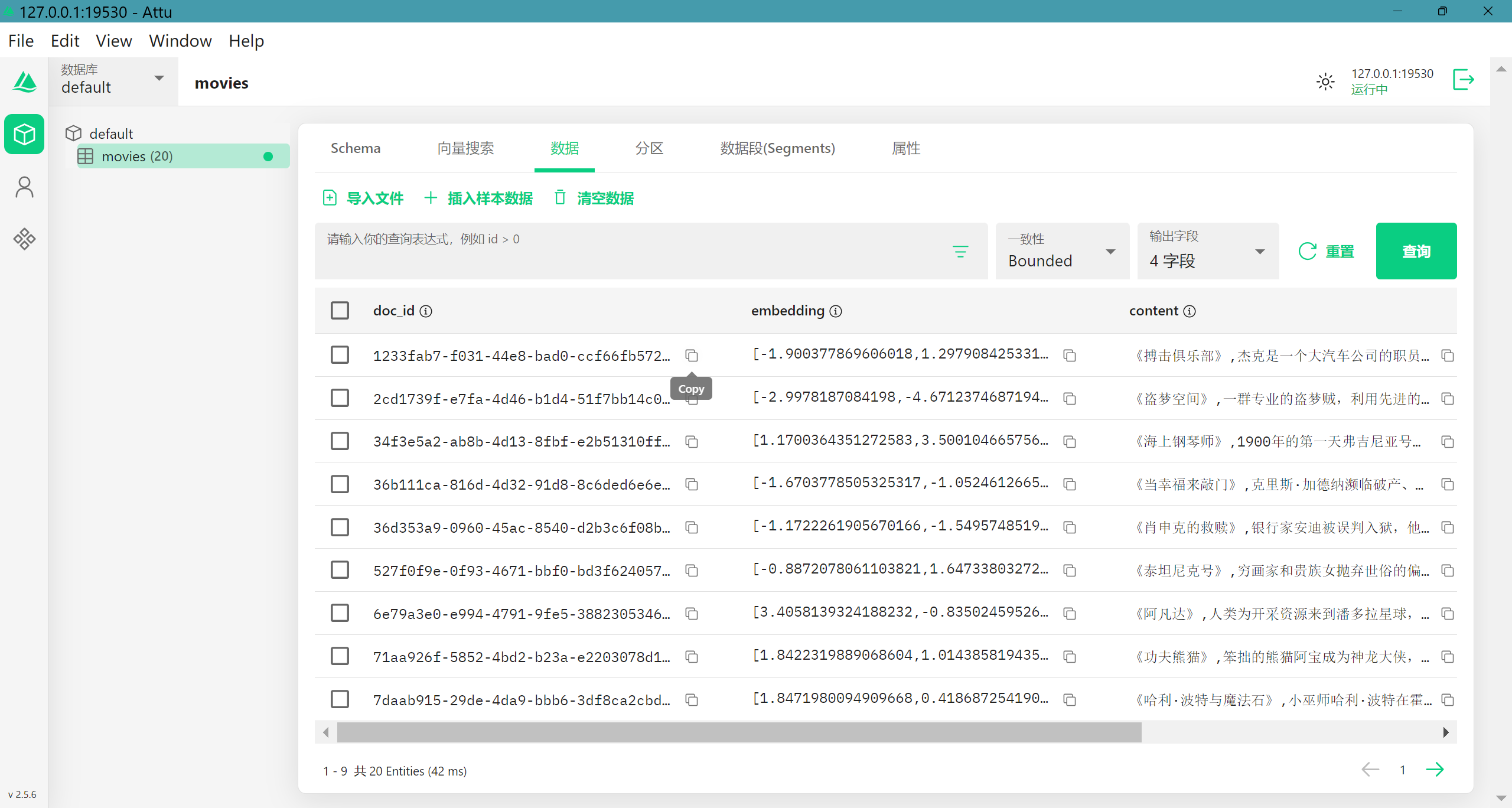
向量数据库中的电影数据
我们调用接口向程序提出想看《哪吒》类型的电影(原谅我没有写漂亮的前端界面)
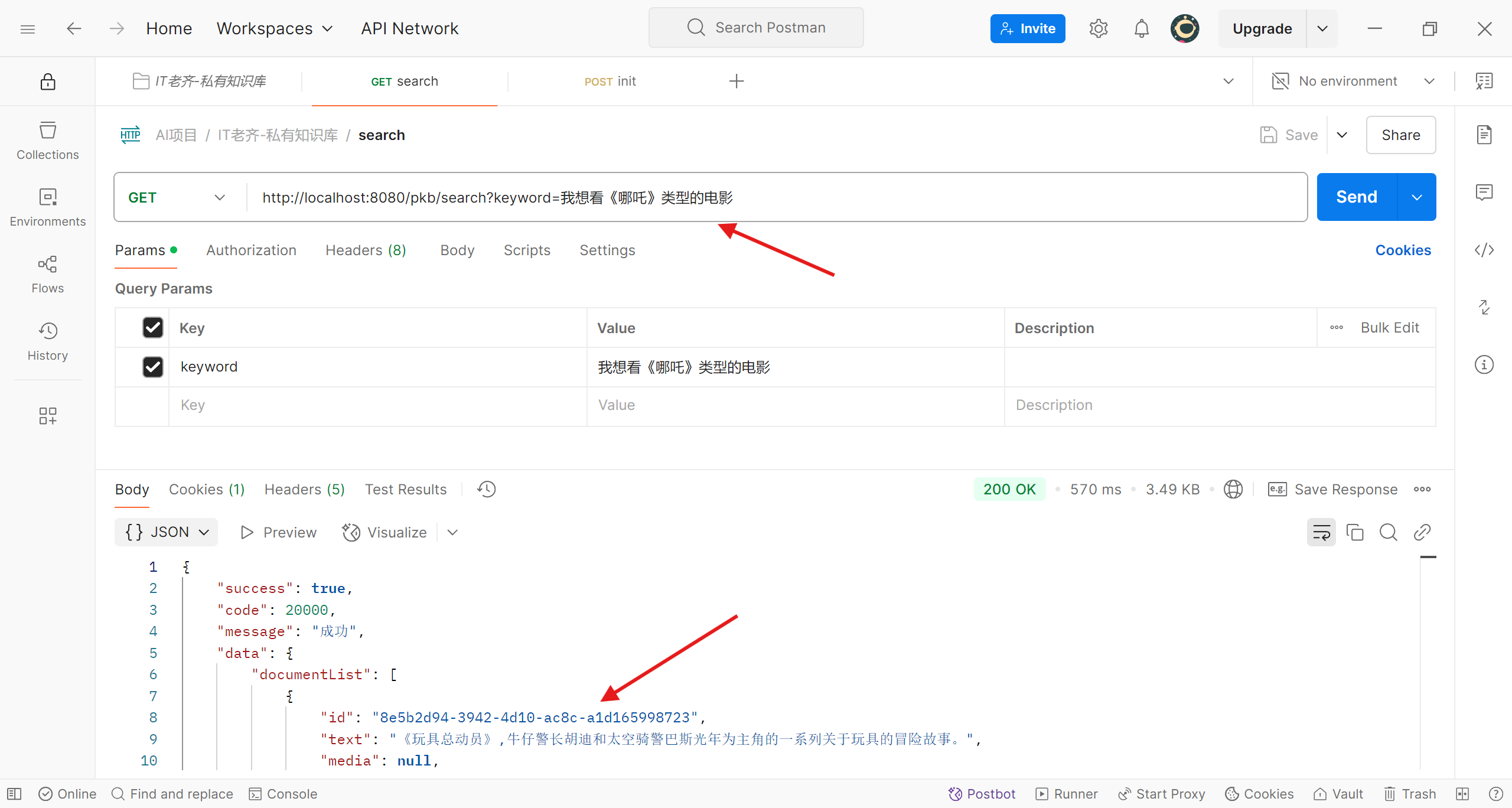
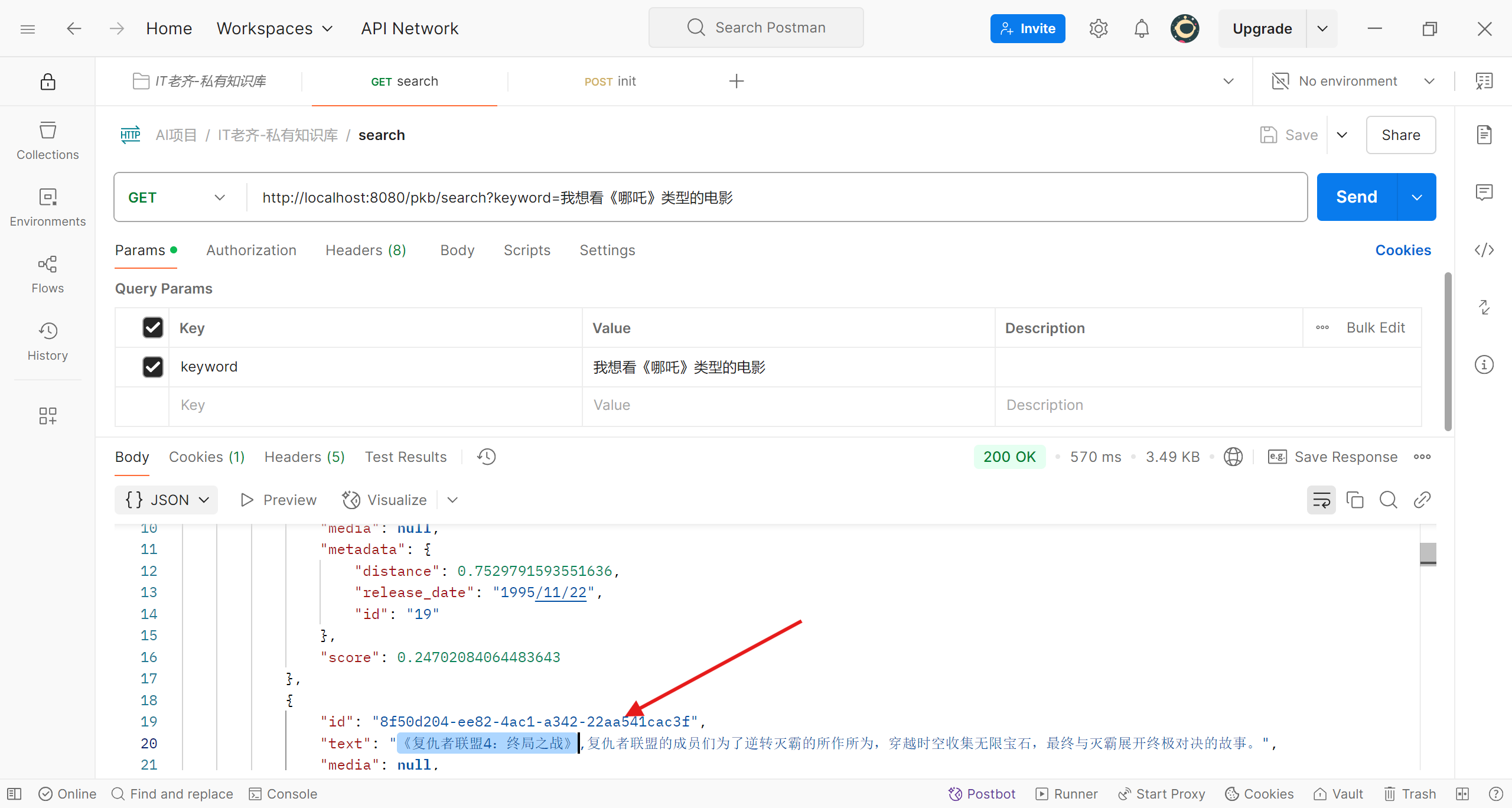
《哪吒》类型电影的推荐结果
程序向我们推荐了《玩具总动员》、《复仇者联盟4:终局之战》等;我们换换口味,这次希望看爱情电影,把想法告诉程序
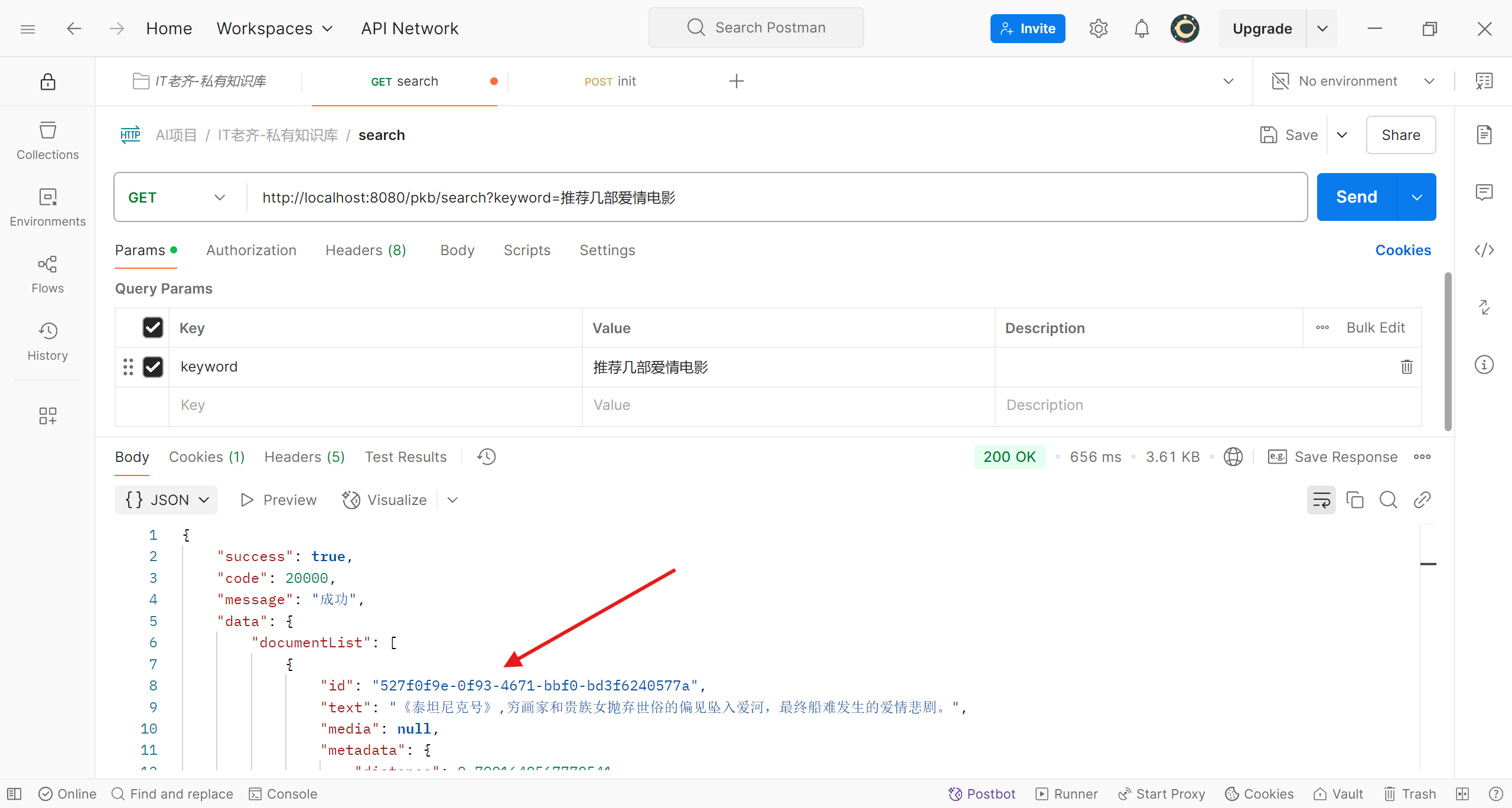
爱情电影推荐结果
可以看到程序首先为我们推荐了《泰坦尼克号》,相似度最高的推荐还是比较符合的,但由于数据源只有20部电影,接下来的推荐就不太准确了;那么接下来我们看看如何实现。
实现
系统架构
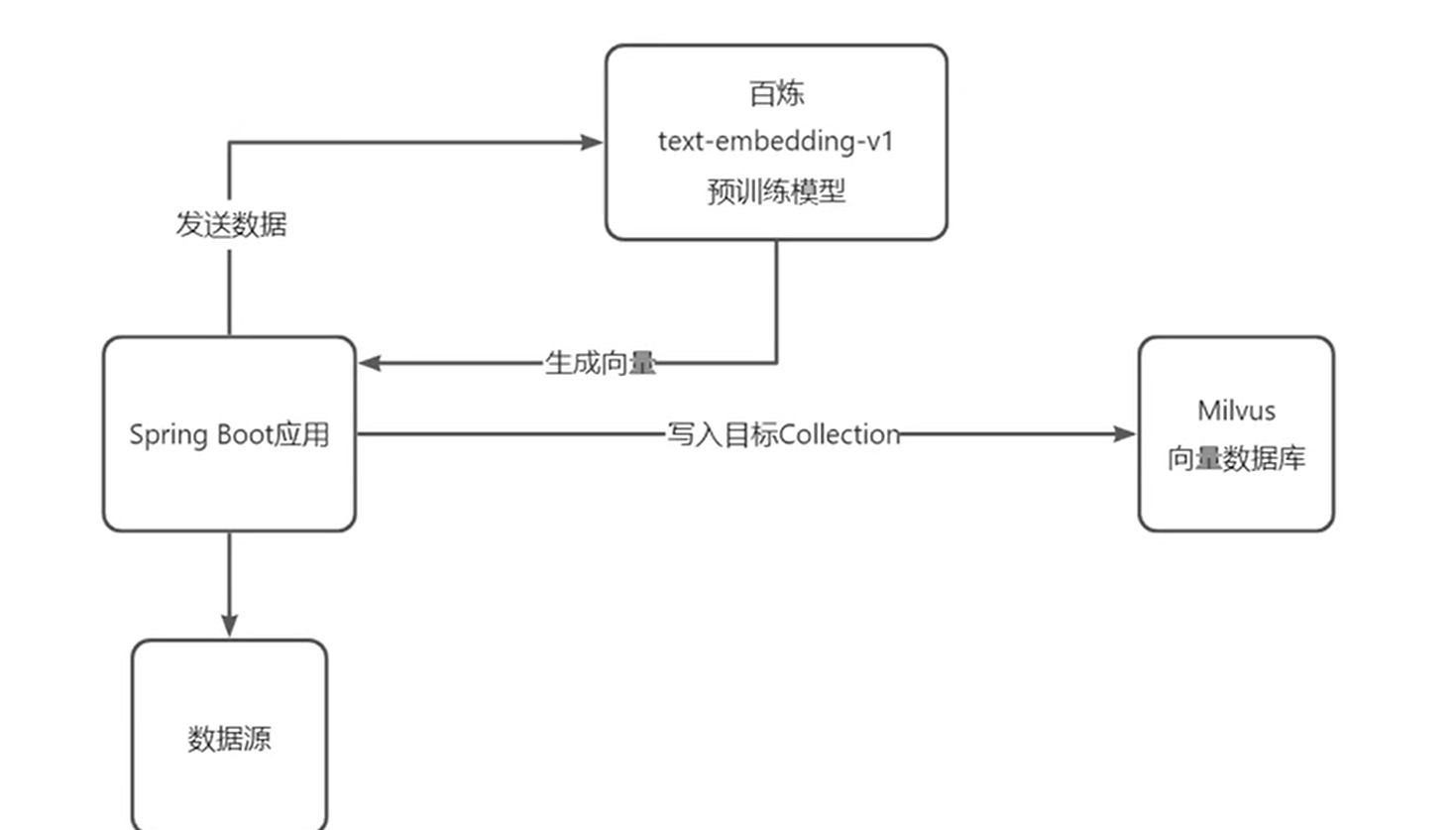
数据初始化
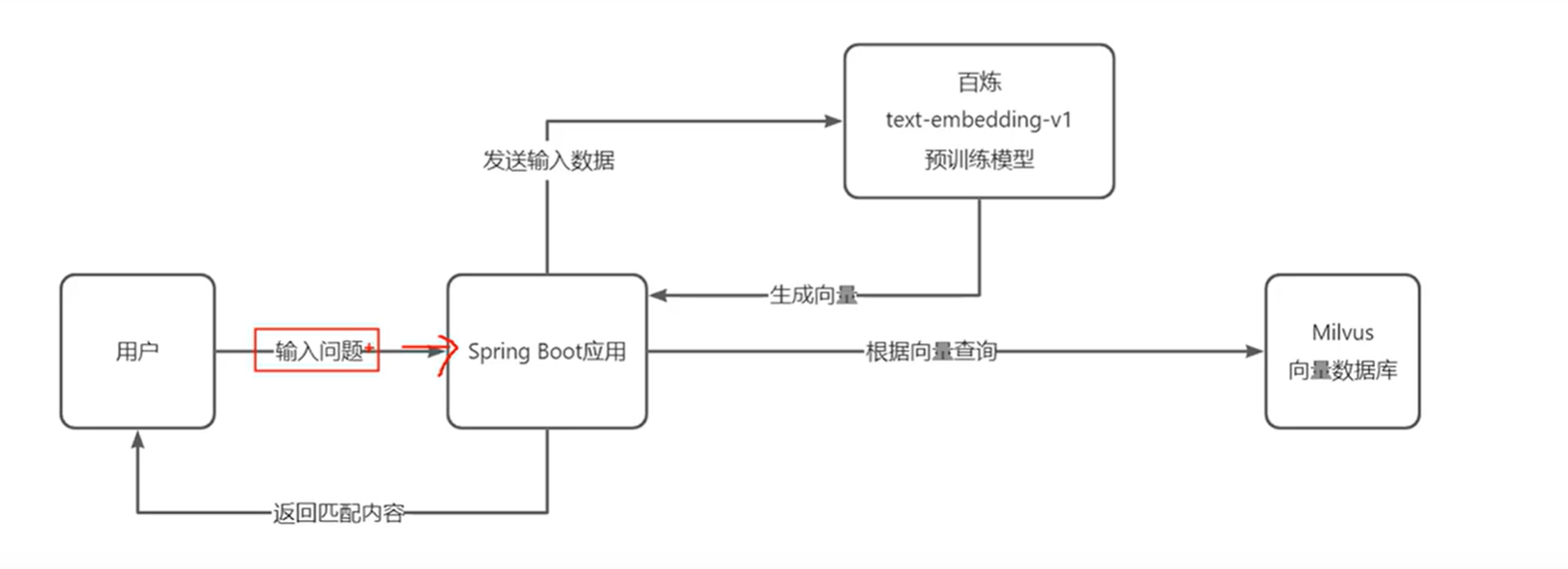
数据查询
由图可以看到,这个系统现在简单的分为两个阶段,在数据初始化阶段,我们首先通过springboot应用程序读取本地的数据源(本次使用csv文件),将其发送到阿里云百炼的预训练模型(即向量模型),由其帮我们生成向量数据,接收到其生成的向量数据,再写入本地的Milvus向量数据库;在数据查询阶段,我们在springboot应用通过接口接收用户的查询问题,将其发送到预训练模型生成向量,接收到生成的向量数据,再根据该数据从向量数据库中匹配相关性最强的查询结果。
环境准备
向量模型
本次我们使用阿里云百炼的通用文本态向量,为什么要使用阿里云百炼呢,因为可以白嫖50万次的tokens,当然也可以使用别家的产品,或者自己部署,不过自己部署又足够再写几篇博客了。
登录阿里云,开通‘阿里云百炼’,进入‘模型广场’,点击‘向量模型’-‘通用文本态向量-v1’,获取模型名称(箭头所指),再新建一个ApiKey,保存好模型名称和ApiKey;
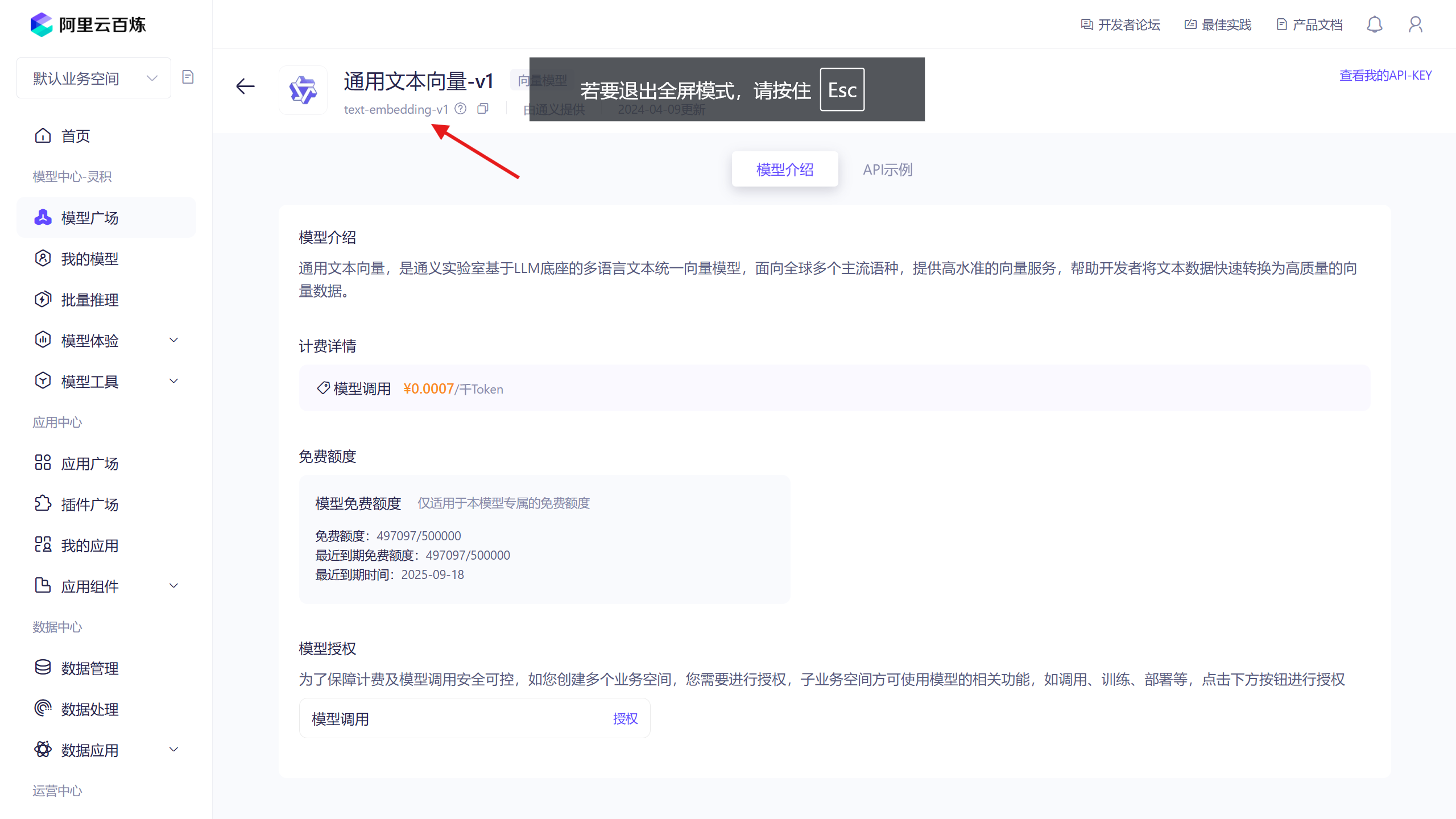
模型名称:text-embedding-v1
ApiKey
- 注:因为这个demo中我们准备的数据源是文本,所以这里我们还是使用文本态向量,阿里云百炼也有通用多模态向量,可以将文本、图片、视频等等文件向量化,如果有需要也可以使用多模态向量。
向量数据库Milvus
我们选择docker-compose的方式安装Milvus,具体安装步骤可以查看官方文档,当然,必须先安装好docker和docker-compose,我把Milvus的docker-compose.yaml文件也贴在这里:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| services:
etcd:
container_name: milvus-etcd
image: quay.io/coreos/etcd:v3.5.18
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
- ETCD_QUOTA_BACKEND_BYTES=4294967296
- ETCD_SNAPSHOT_COUNT=50000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd
command: etcd -advertise-client-urls=http://127.0.0.1:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
healthcheck:
test: ["CMD", "etcdctl", "endpoint", "health"]
interval: 30s
timeout: 20s
retries: 3
minio:
container_name: milvus-minio
image: minio/minio:RELEASE.2023-03-20T20-16-18Z
environment:
MINIO_ACCESS_KEY: minioadmin
MINIO_SECRET_KEY: minioadmin
ports:
- "9001:9001"
- "9000:9000"
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_data
command: minio server /minio_data --console-address ":9001"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
standalone:
container_name: milvus-standalone
image: milvusdb/milvus:v2.5.6
command: ["milvus", "run", "standalone"]
security_opt:
- seccomp:unconfined
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9091/healthz"]
interval: 30s
start_period: 90s
timeout: 20s
retries: 3
ports:
- "19530:19530"
- "9091:9091"
depends_on:
- "etcd"
- "minio"
networks:
default:
name: milvus
|
可以看到,对外暴露两个端口号,分别是可以通过网页访问的管理端口9091和工作端口19530;安装完毕后,我们可以通过9091访问
使用浏览器通过9091端口访问
那么19530端口呢,这个端口就相当于MySQL的3306端口,我们可以通过一个类似Navicat的客户端软件访问它,这个客户端叫’attu‘,点击链接下载,安装后启动即可;
attu启动页面
启动后填写正确的IP、端口和数据库名称,就可以连接了
连接到向量数据库
点击数据库名称(如’default‘)进入数据库,我们可以新建一个’collection‘(类似数据库的表)
进入数据库default
我们新建一个名称为‘movies’的collection,包含4个字段,分别为doc_id-VarChar(36)-主键、embedding-FloatVector(1536)-向量、content-VarChar(65335)-文本、metadata-JSON-元数据;向量的长度由使用的向量模型决定(这里使用阿里云百炼的通用文本模型)
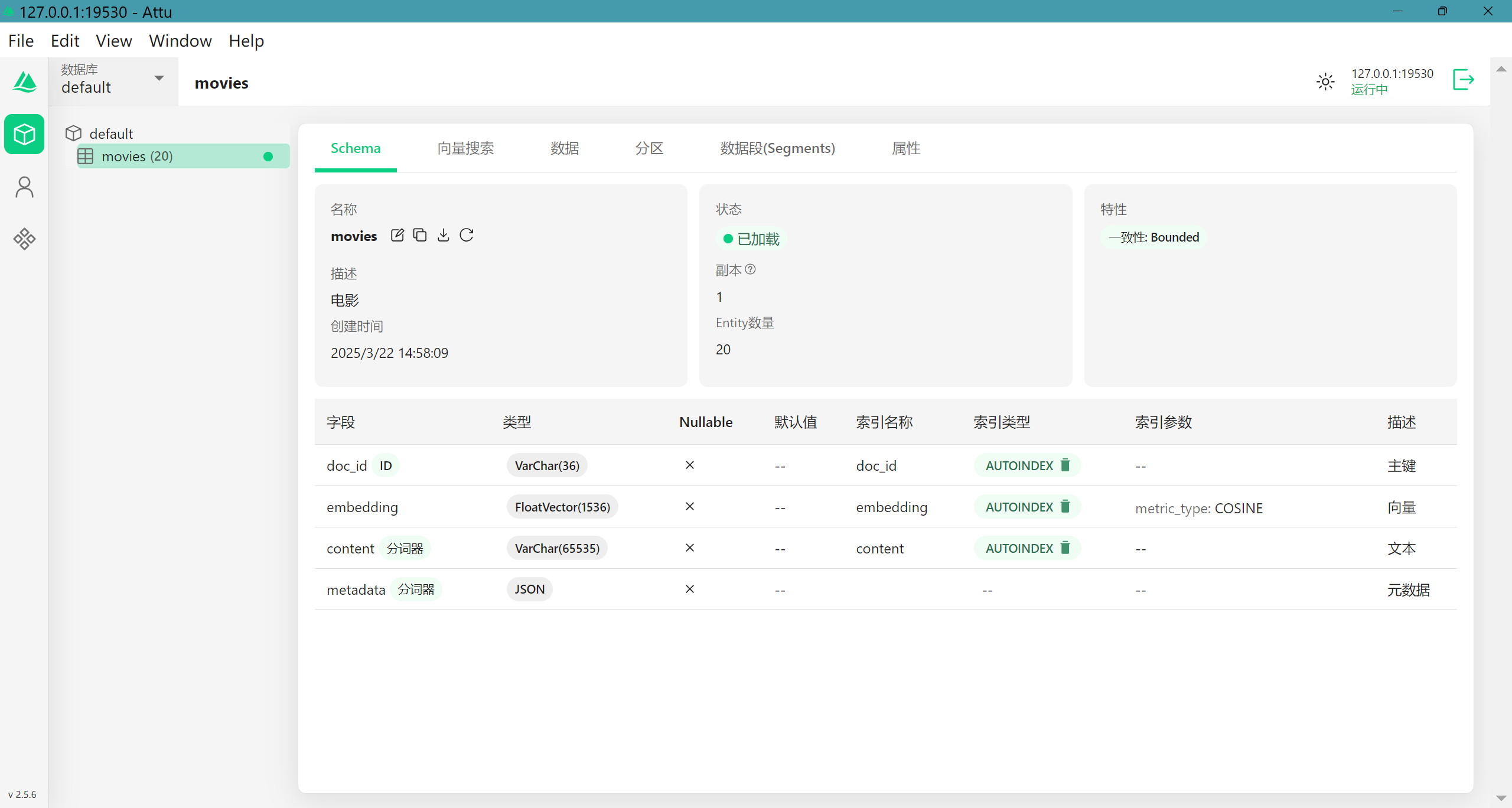
这样我们的milvus就准备好了
SpringBoot工程
新建项目
前期的准备工作差不多了,我们现在开始写代码,先新建一个项目工程,我的是’qiuli-pkb‘
添加依赖
JDK 21、SpringBoot 3.3.10、SpringAIAlibaba 1.0.0-M5.1,部分pom文件如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
| <project>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.3.10</version>
<relativePath/>
</parent>
<properties>
<java.version>21</java.version>
<maven.compiler.source>21</maven.compiler.source>
<maven.compiler.target>21</maven.compiler.target>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0-SNAPSHOT</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.7.15</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter</artifactId>
<version>1.0.0-M5.1</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-milvus-store-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>io.grpc</groupId>
<artifactId>grpc-core</artifactId>
<version>1.70.0</version>
</dependency>
<dependency>
<groupId>io.grpc</groupId>
<artifactId>grpc-netty-shaded</artifactId>
<version>1.70.0</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-csv</artifactId>
<version>1.9.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.13.0</version>
<configuration>
<source>21</source>
<target>21</target>
<annotationProcessorPaths>
<path>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</path>
</annotationProcessorPaths>
</configuration>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>
</project>
|
- 因为AI发展的很快,现在的包都很不稳定,甚至于Maven官方仓库都不提供SpringAiAlibaba 的依赖,所以我们需要在pom文件中引入’repository‘模块,直接从spring的仓库下载依赖;在项目的pom文件中引入了spring仓库,还要在maven的配置文件中表明spring-milestones和spring-snapshots相关的依赖不在maven原本配置的仓库中下载,要在setting.xml文件中修改
mirrorOf项为如下内容:
1
2
3
4
5
6
| <mirror>
<id>aliyunmaven</id>
<mirrorOf>*,!spring-milestones,!spring-snapshots</mirrorOf>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
|
- 为了连接Milvus向量数据库,我们引入了spring-ai-milvus-store-spring-boot-starter,这个包为我们进行了自动装配,使得我们可以直接使用SpringAi包中的一些bean,如果我们使用spring-ai-milvus-store这个包,这些bean就需要我们手动引入项目中,例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| @Bean
public VectorStore vectorStore(MilvusServiceClient milvusClient, EmbeddingModel embeddingModel) {
MilvusVectorStoreConfig config = MilvusVectorStoreConfig.builder()
.withCollectionName("test_vector_store")
.withDatabaseName("default")
.withIndexType(IndexType.IVF_FLAT)
.withMetricType(MetricType.COSINE)
.build();
return new MilvusVectorStore(milvusClient, embeddingModel, config);
}
@Bean
public MilvusServiceClient milvusClient() {
return new MilvusServiceClient(ConnectParam.newBuilder()
.withAuthorization("minioadmin", "minioadmin")
.withUri(milvusContainer.getEndpoint())
.build());
}
|
添加yaml文件
在项目的resources目录创建application.yaml文件,添加如下内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| spring:
application:
name: qiuli-pkb
ai:
vectorstore:
milvus:
client:
host: localhost
port: 19530
database-name: default
collection-name: movies
embedding-dimension: 1536
index-type: ivf_flat
metric-type: cosine
embedding-field-name: embedding
initialize-schema: true
dashscope:
api-key: sk-xxx
read-timeout: 3600
embedding:
options:
model: text-embedding-v1
dimensions: 1536
server:
port: 8080
logging:
level:
root: info
|
我们来解释一下这些配置项
| 属性 |
描述 |
默认值 |
| spring.ai.vectorstore.milvus.client.host |
我们之前安装的向量数据库的IP |
localhost |
| spring.ai.vectorstore.milvus.client.port |
我们之前安装的向量数据库的Port |
19530 |
| spring.ai.vectorstore.milvus.database-name |
要使用的 Milvus 数据库的名称。 |
default |
| spring.ai.vectorstore.milvus.collection-name |
用于存储向量的 Milvus 集合名称 |
vector_store |
| spring.ai.vectorstore.milvus.initialize-schema |
是否初始化 Milvus 后端 |
false |
| spring.ai.vectorstore.milvus.embedding-dimension |
要存储在 Milvus 集合中的向量的维度。 |
1536 |
| spring.ai.vectorstore.milvus.index-type |
要为 Milvus 集合创建的索引的类型。 |
IVF_FLAT |
| spring.ai.vectorstore.milvus.metric-type |
用于 Milvus 集合的度量类型。 |
COSINE |
| spring.ai.dashscope.api-key |
填入之前准备好的向量模型的api-key |
|
| spring.ai.dashscope.read-timeout |
读取超时时间 |
|
| spring.ai.dashscope.embedding.options.model |
填入之前准备好的向量模型的名称 |
|
| spring.ai.dashscope.embedding.options.dimensions |
向量的维度,与spring.ai.vectorstore.milvus.embedding-dimension保持一致 |
1536 |
|
|
|
更多的配置项我就不一一列出了,可以查看文档了解;至于为什么向量维度是1536,这是向量模型中给出的数据
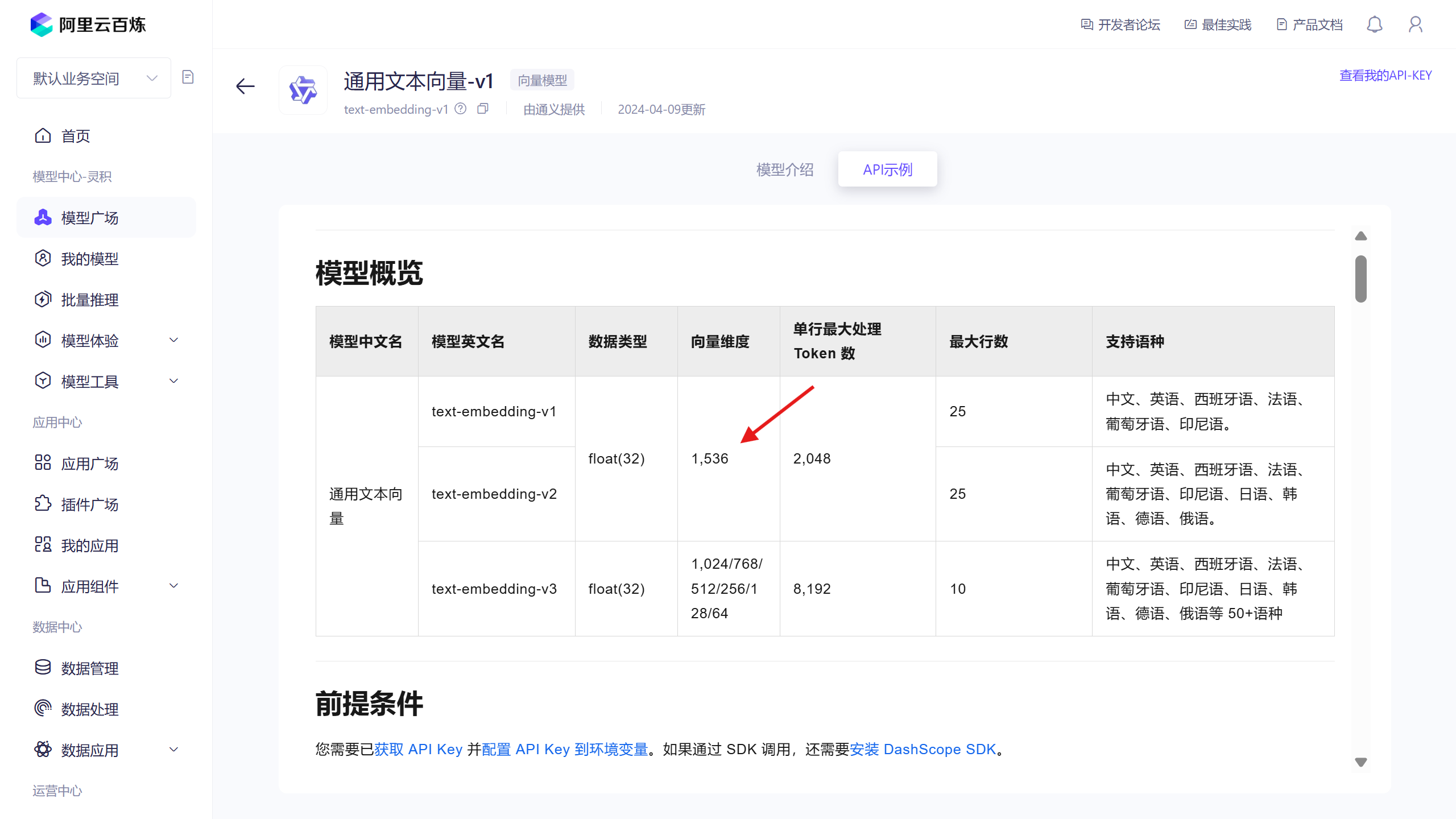
代码实现
读取csv文件
这里我们准备一份csv文件作为我们的数据源,文件如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| id,title,overview,release_date
1,《泰坦尼克号》,穷画家和贵族女抛弃世俗的偏见坠入爱河,最终船难发生的爱情悲剧。,1997/12/19
2,《阿凡达》,人类为开采资源来到潘多拉星球,与当地纳美人发生的一系列故事。,2009/12/18
3,《千与千寻》,少女千寻意外进入神灵异世界后,为了救爸爸妈妈,经历了很多磨难的奇幻旅程。,2001/7/20
4,《哈利·波特与魔法石》,小巫师哈利·波特在霍格沃茨魔法学校的第一年,探寻魔法石背后秘密的冒险。,2001/11/16
5,《指环王1:护戒使者》,弗罗多和他的伙伴们踏上护送魔戒毁灭之旅的开始。,2001/12/19
6,《星际穿越》,一组宇航员穿越虫洞来为人类寻找新家园的冒险之旅。,2014/11/7
7,《盗梦空间》,一群专业的盗梦贼,利用先进的技术进入他人梦境,从他人的潜意识中进行信息提取或者植入的故事。,2010/7/16
8,《疯狂动物城》,兔子朱迪通过自己努力奋斗完成自己儿时的梦想,成为动物警察,在城市中与狐狸尼克一同查案的故事。,2016/3/4
9,《功夫熊猫》,笨拙的熊猫阿宝成为神龙大侠,与恶势力战斗保卫和平谷的故事。,2008/6/6
10,《海上钢琴师》,1900年的第一天弗吉尼亚号上的烧炉工丹尼在头等舱的钢琴上捡到一个弃婴,为他取名为1900,1900长大后成为一名钢琴天才的传奇一生。,1998/10/28
11,《三傻大闹宝莱坞》,三位主人公法罕、拉加与兰彻间的大学故事,兰彻是个与众不同的大学生,他用他的智慧打破学院墨守成规的传统教育观念。,2009/12/25
12,《忠犬八公的故事》,教授收养了一只小秋田犬八公,八公每天在车站等待教授下班,即使教授去世后它依然坚持等待的感人故事。,2009/8/8
13,《当幸福来敲门》,克里斯·加德纳濒临破产、老婆离家,他带着儿子住地铁站厕所、住收容所,但他凭借自己的努力最终成为知名金融投资家的励志故事。,2006/12/15
14,《搏击俱乐部》,杰克是一个大汽车公司的职员,患有严重的失眠症,对周围的一切充满危机和憎恨,他参加了一个叫搏击俱乐部的地下组织,从而引发一系列故事。,1999/10/15
15,《肖申克的救赎》,银行家安迪被误判入狱,他不动声色、步步为营地谋划自我拯救并最终成功越狱,同时也救赎狱中好友瑞德的故事。,1994/9/23
16,《寄生虫》,基宇出生在一个贫穷的家庭之中,和妹妹基婷以及父母在狭窄的地下室里过着相依为命的日子。一天,基宇的同学上门拜访,他告诉基宇,自己在一个有钱人家里给他们的女儿做家教,现在自己要出国留学,所以将家教的职位暂时转交给基宇。就这样,基宇来到了朴社长家中,并且见到了他的太太,没过多久,基宇的妹妹和父母也如同寄生虫一般的进入了朴社长家里工作。,2019/5/30
17,《小丑》,亚瑟·弗莱克是一个和母亲住在破旧公寓里,努力想要成为一名脱口秀演员的男人。他患有一种会突然放声大笑的精神疾病,这使他在生活中遭遇诸多不顺,在社会的压迫下逐渐走向黑暗的故事。,2019/10/4
18,《复仇者联盟4:终局之战》,复仇者联盟的成员们为了逆转灭霸的所作所为,穿越时空收集无限宝石,最终与灭霸展开终极对决的故事。,2019/4/24
19,《玩具总动员》,牛仔警长胡迪和太空骑警巴斯光年为主角的一系列关于玩具的冒险故事。,1995/11/22
20,《黑豹》,特查拉在其父亲——前黑豹去世之后,回到了瓦坎达担任国王,然而当旧敌重现时,作为黑豹的他必须挺身而出保护他的人民和国家。,2018/2/16
|
可以看到,有四列字段,分别为id、标题、介绍、发行时间,我们写一个枚举类将字段序列号与名称对应
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| @Getter
@ToString
@AllArgsConstructor
public enum CrowdHeaderEnum {
ID(0, "id"),
TITLE(1, "title"),
OVERVIEW(2, "overview"),
RELEASE_DATE(3, "release_date");
int index;
String name;
}
|
添加读取csv文件的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
@Deprecated
public static List<Document> getCsvRowList(String path) {
List<Document> result = new ArrayList<>();
try {
CsvData data = CsvUtil.getReader().read(FileUtil.file(path));
if (Objects.isNull(data) || Objects.isNull(data.getRow(0)) || Objects.isNull(data.getRow(1))) {
log.error("read csv file empty!,path:{}", path);
}
for (int i = 1; i < data.getRowCount(); i++) {
CsvRow row = data.getRow(i);
String title = row.get(CrowdHeaderEnum.TITLE.getIndex());
String overview = row.get(CrowdHeaderEnum.OVERVIEW.getIndex());
Document document = new Document(title + "," + overview,
Map.of(CrowdHeaderEnum.ID.getName(),
row.get(CrowdHeaderEnum.ID.getIndex()),
CrowdHeaderEnum.RELEASE_DATE.getName(),
row.get(CrowdHeaderEnum.RELEASE_DATE.getIndex())));
result.add(document);
}
} catch (Exception e) {
log.error("ReadFileUtils#getCsvRowList fail!{}", Throwables.getStackTraceAsString(e));
}
return result;
}
|
初始化向量数据
将从csv文件中读取到的数据通过预训练模型转化为向量,并添加到向量数据库中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| @Resource
VectorStore vectorStore;
@Value("${pkb.movies.file-path}")
private String filePaht;
@Override
public void init() {
List<Document> documents = new ArrayList<>();
try {
documents = ReadFileUtil.getCsvRowList(filePaht);
log.info("com.qiuli.pkb.service.impl.PkbServiceImpl.init, file info : " + documents.toString());
} catch (Exception e) {
log.info(e.getMessage());
}
vectorStore.add(documents);
}
|
我们还是使用接口来触发
1
2
3
4
5
| @PostMapping("/init")
public Result init() {
pkbService.init();
return Result.ok().message("数据初始化到向量数据库成功");
}
|
相似性检索
我们可以通过一个问题或者一句对话来检索,同样,框架会先将我们的参数提交到预训练模型向量化,再与向量数据库中的数据匹配,这里我没有添加其他的过滤条件,只是安装相似度选取,选取相似度最高的10条
1
2
3
4
5
6
7
| @Override
public List<Document> search(String keyword) {
SearchRequest searchRequest =
new SearchRequest().builder().query(keyword).topK(10).similarityThresholdAll().build();
List<Document> documents = vectorStore.similaritySearch(searchRequest);
return documents;
}
|
同样查询也需要一个接口
1
2
3
4
5
6
7
8
9
10
11
12
|
@GetMapping("/search")
public Result search(@RequestParam String keyword) {
List<Document> documentList = pkbService.search(keyword);
log.info(documentList.toString());
return Result.ok().data("documentList", documentList);
}
|
在向量数据库中新建collection
现在我们回到向量数据库的客户端attu,新建一个collection,名称为movies,我之前已经建好了,这里就不重新建了
建好的collection
我们来说说其中的4个字段,doc_id是id不再解释;embedding就是大模型返回的向量值;content是我们提交给大模型的文本,我这里使用的是’title+overview‘,即标题+内容简介;metadata是元数据,为json格式,可以用来过滤查询结果,我将电影的发型日期添加进了元数据;我们来看看数据的样子
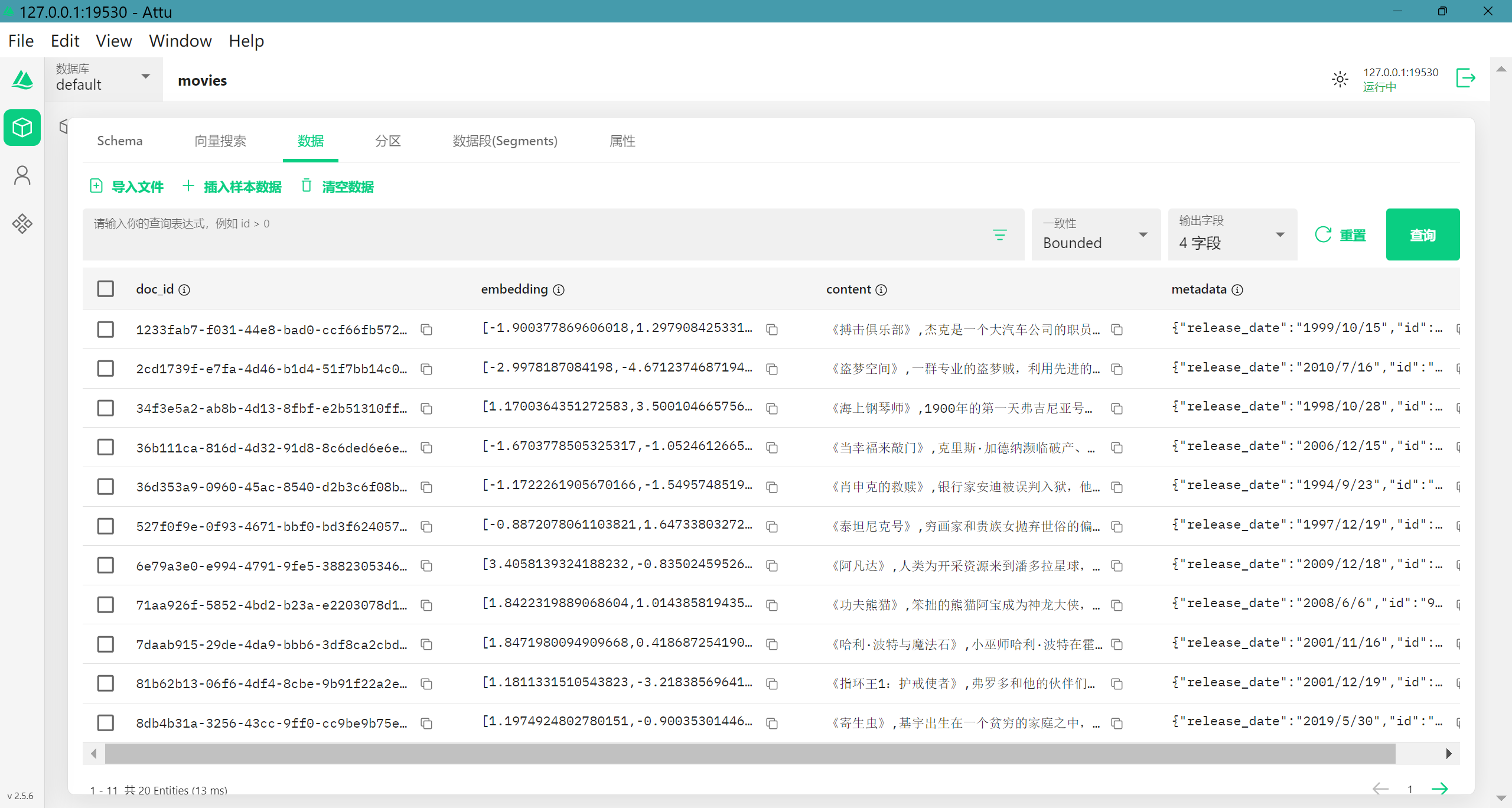
电影的向量数据
测试
我们使用Postman,调用数据初始化的接口
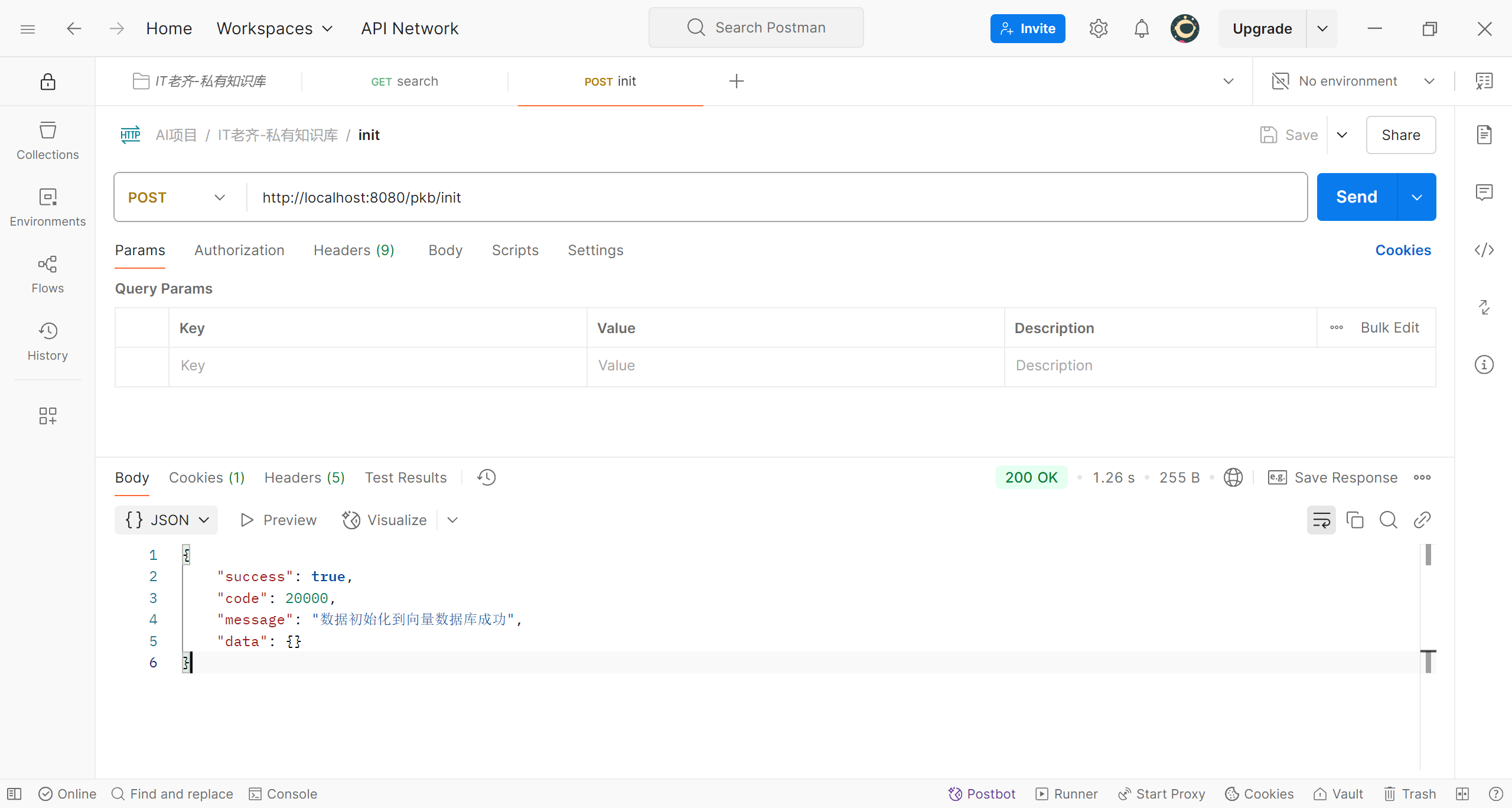
调用数据初始化接口
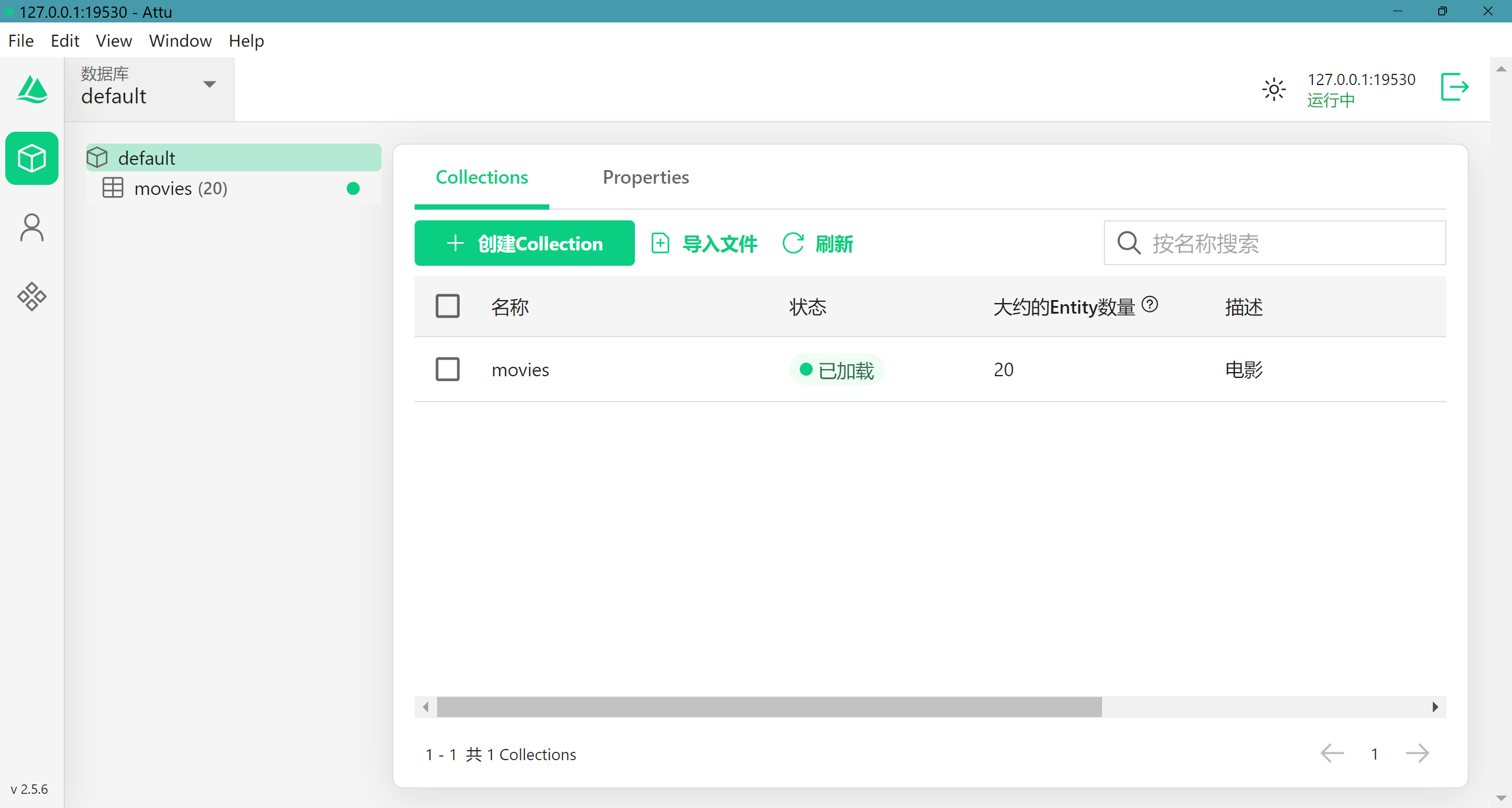
数据已经加载
来到attu客户端,可以看到名称movies的collection中’大约的Entity数量‘为20,说明数据已经正确加载,我们再来查询一下,这次我们想看科幻片,程序为我们推荐了《阿凡达》
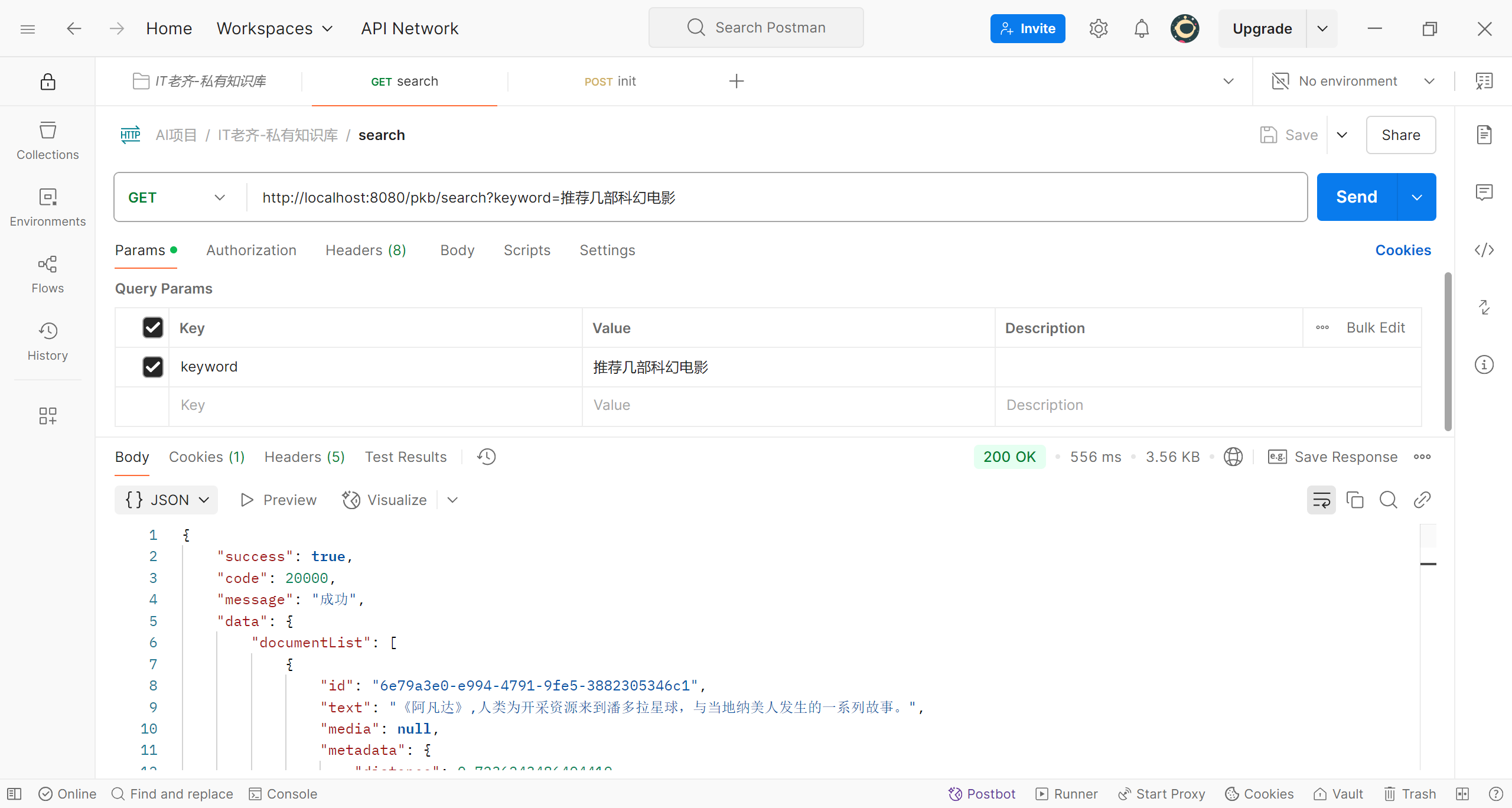
让程序推荐科幻片
TODO
这篇文章中我们实现的是个简单的demo,有很多不完善的地方;而且这个系统有个最大的问题是如何准备数据源,特别是符合我们要求的能够使用的数据,这就涉及到我们日常要如何收集整理日志等等,还有一些大数据的内容,我们在后面的文章中再详细写。